
dilluns, 12 de setembre del 2016
dissabte, 1 de març del 2014
Stack Overflow, número de consultes sobre Java, PHP, Python i .NET
Tot programador coneix StackOverflow, és una web gamificada de preguntes i respostes per a desenvolupadors d'aplicacions. Totes les dades del portal són públiques excepte els vots que emeten els usuaris entre si. Amb les dades de la web he elaborat aquestes estadístiques:
1) Número de consultes mensuals dels llenguatges Java, PHP, Python i .NET

Nota: He englobat dins de cada llenguatge els següents tags:
Java: 'java', 'java-me', 'java-ee', 'javafx', 'javafx-2'
PHP: 'php%', 'zend-framework', 'codeigniter'
Python: like 'python%', 'django'
.NET: '.net%', 'C#' , 'linq', 'VB%NET'
Sobta veure que .NET rep molt poques consultes, però hem de pensar que disposen del seu propi forum ( MSDN ). També cal notar com al 2010 el número de preguntes mensuals sobre aquests 4 llenguatges era de unes 5k mentre que al 2014 ja ens apropem a les 20K preguntes mensuals per Java i PHP.
2) Estacionalitat de les consultes.

Es curiós comprovar com l'estacionalitat de PHP i Java és tant semblant. Què passa al juny amb aquests programadors?
3) Frameworks django vs RoR:
 Aquest gràfic em diu que potser hauria d'haver triat RoR en comptes de django com a llenguatge de capcelera, però no ho puc evitar, el python és genial.
Aquest gràfic em diu que potser hauria d'haver triat RoR en comptes de django com a llenguatge de capcelera, però no ho puc evitar, el python és genial.
4) Evolució Entity Framework

Aquesta és l'evolució del número de preguntes d'EF. L'he inclòs a l'estadística perquè a l'agost del 2012 Rowan Miller, gurú d'EF, va demanar que les preguntes d'aquest producte es realitzessin a SO:
 Val a dir que aquestes estadístiques no serveixen massa per comparar un llenguatge amb un altre. Per exemple al cas de .NET apareixen 'poques' preguntes a SO, això és degut a que disposa del seu propi foro de programadors i és molt actiu. La conclusió graciosa a la que he arribat és que els programadors de Java i PHP s'en van de vacances junts al juny, mentre que els de python les agafen al setembre. I la seriosa és que StackOverflow és una història de win-win, fan una grandíssima aportació a la comunitat de programadors i a canvi ofereixen a les empreses la base de dades d'usuaris del portal (els que reben invitació per ser-hi i l'accepten) per a les operacions de fixatges.
Val a dir que aquestes estadístiques no serveixen massa per comparar un llenguatge amb un altre. Per exemple al cas de .NET apareixen 'poques' preguntes a SO, això és degut a que disposa del seu propi foro de programadors i és molt actiu. La conclusió graciosa a la que he arribat és que els programadors de Java i PHP s'en van de vacances junts al juny, mentre que els de python les agafen al setembre. I la seriosa és que StackOverflow és una història de win-win, fan una grandíssima aportació a la comunitat de programadors i a canvi ofereixen a les empreses la base de dades d'usuaris del portal (els que reben invitació per ser-hi i l'accepten) per a les operacions de fixatges.
Qualsevol proposta per explorar dades de l'SO serà benvinguda.
1) Número de consultes mensuals dels llenguatges Java, PHP, Python i .NET
Nota: He englobat dins de cada llenguatge els següents tags:
Java: 'java', 'java-me', 'java-ee', 'javafx', 'javafx-2'
PHP: 'php%', 'zend-framework', 'codeigniter'
Python: like 'python%', 'django'
.NET: '.net%', 'C#' , 'linq', 'VB%NET'
Sobta veure que .NET rep molt poques consultes, però hem de pensar que disposen del seu propi forum ( MSDN ). També cal notar com al 2010 el número de preguntes mensuals sobre aquests 4 llenguatges era de unes 5k mentre que al 2014 ja ens apropem a les 20K preguntes mensuals per Java i PHP.
2) Estacionalitat de les consultes.
Es curiós comprovar com l'estacionalitat de PHP i Java és tant semblant. Què passa al juny amb aquests programadors?
3) Frameworks django vs RoR:
4) Evolució Entity Framework
Aquesta és l'evolució del número de preguntes d'EF. L'he inclòs a l'estadística perquè a l'agost del 2012 Rowan Miller, gurú d'EF, va demanar que les preguntes d'aquest producte es realitzessin a SO:
Qualsevol proposta per explorar dades de l'SO serà benvinguda.
dilluns, 25 de novembre del 2013
Avaluació de la docència de la Unitat Formativa 3: Desenvolupament web en entorn servidor - Tècniques d’accés a dades.
Aquest és el resultat de l'enquesta sobre assoliment de resultats de la UF3, Desenvolupament web en entorn servidor - Tècniques d’accés a dades. Hem treballat l'accés a dades amb PHP mitjançant PDO (+SQL), Entity Framework 6 i models django.
 Del punt 1.7 ( i A.7) només s'ha fet teoria, no exercicis. És destacable com els exercicis són bàsics per a l'assoliment de la materia en aquest cicle.
Del punt 1.7 ( i A.7) només s'ha fet teoria, no exercicis. És destacable com els exercicis són bàsics per a l'assoliment de la materia en aquest cicle.
dijous, 14 de novembre del 2013
Com fer el deploy d'app django actualitzat a dinahosting
Dinahosting suporta aplicacions django, per defecte django1.4 i python2.6.5 (nov 2013).
Nosaltres actualitzarem el django a la darrera versió usant un virtualenv.
Cal que la teva imatge de hosting sigui python / node.js, si no ho és, has d'anar a la eina storm i canviar-ho ( Hosting / Administrar / STORM ). T'ha de quedar així:

Ara cal entrar per ssh:
1) Crear usuari ftp i posar-li password.
2) ssh -p 22 nomUsuariFtp@www.dominiQueSigui.cat
Pots posar l'aplicació allà on vulguis, jo l'he posat sota de www, de manera que m'ha quedat un arbre com aquest:
home
gratia
django16p27
.htaccess (1)www.htaccess (2)ping2u.wsgiping2umanage.pyping2usettings.py
- django16p27 és un virtualenv amb el django 1.6 instal·lat, mira al final del manual si no saps com crear-lo.
- gratia és el meu usuari
- ping2u és la aplicació que vols fer rodar (mira el final del document si no saps crear-la)
- El primer .htaccess l'he deixat tal com ve.
- El segon .htaccess és el que cal adaptar, ha de quedar com aquest:
RewriteEngine OnRewriteCond %{REQUEST_FILENAME} !-fRewriteRule ^(.*)$ /ping2u.wsgi/$1 [QSA,L]
- El fitxer 'ping2u.wsgi' t'ha de quedar com aquest:
import os, sysimport site# Remember original sys.path.prev_sys_path = list(sys.path)site.addsitedir('/home/gratia/django16py27/lib/python2.6/ site-packages/') sys.path.append('/home/gratia/www/ping2u') # Posar els paths de l'entorn virtual davant dels per defecte.new_sys_path = []for item in list(sys.path):if item not in prev_sys_path:new_sys_path.append(item)sys.path.remove(item)sys.path[:0] = new_sys_pathos.environ['DJANGO_SETTINGS_MODULE'] = 'ping2u.settings' from django.core.handlers.wsgi import WSGIHandlerapplication = WSGIHandler()
- Creació del virtualenv:
cd ~virtualenv django16p27source ~/django16p27/bin/activatepip install django
- Per crear l'aplicació de test ping2u:
cd wwwdjango-admin.py startproject ping2u
A l'aplicació he provocat un error (divisió per 0) per veure si està rodant realment amb 1.6:

L'.htaccess (1) és aquest:
#### DHGENERATED## NO EDITAR MANUALMENTE!!!!##AddHandler mod_python .pyPythonHandler mod_python.publisherPythonDebug OnOptions +ExecCGIAddHandler wsgi-script .wsgi
RewriteEngine On
##REGLAS_NODE##
##FIN_REGLAS_NODE##
 I això és tot. Agraïr a la gent de suport de dinahosting, en especial a A.A. l'ajuda que m'han prestat per poder posar en marxa l'aplicació, els fitxers .htaccess són seus. Una llàstima la versió de python, tant de bo la canviin aviat.
I això és tot. Agraïr a la gent de suport de dinahosting, en especial a A.A. l'ajuda que m'han prestat per poder posar en marxa l'aplicació, els fitxers .htaccess són seus. Una llàstima la versió de python, tant de bo la canviin aviat.Després de tot plegat, aquí la meva aplicació (que encara no sé per a que em serveix) funcionant.
Disclaimer: aquesta guia no és oficial de dinahosting, utilitza-la al teu risc.
dissabte, 9 de novembre del 2013
Quaderns Exercicis FP - Correu del divendres 8 de Novembre
Novetats de Quaderns d'Exercicis FP.


Xavier Sala, Carles Caño, Isaac Muro, Marc Nicolau, Juaky
Gràcies per compartir!
Ja tenim 92 exercicis al portal i pujant!

Per UF el total d'exercicis són els següents ( hi ha UF's equivalents que comparteixen exercicis ):

Xavier Sala, Carles Caño, Isaac Muro, Marc Nicolau, Juaky
Gràcies per compartir!
Com donar les gràcies als companys? Marcar com a útil:

Novetats tècniques
El codi queda resaltat ( merci dani h.):Es poden fer taules ( merci xavi s.):
Les imatges responsives (merci carles c.):



Nota: la manera més fàcil per saber com es fan aquests recursos amb MarkDown és editar l'exercici d'un company que ho hagi fet servir i copiar ;)
Us animo a seguir compartint i disfrutant dels exercicis dels companys i a fer divulgació del portal Quaderns d'Exercicis FP
Tots els suggeriments són benvinguts ... una altre cosa és el temps que tingui per poder-los implementar ;)
dimarts, 29 d’octubre del 2013
Com fer-te el teu propi notificador disponibilitat de Nexus 5
Proliferen pàgines on et pots subscriure a avisos de disponibilitat de productes. Aquí t'explico com fer-te el teu propi notificador Nexus 5 amb unes poques línies de codi.
Necessitarem:
- Una màquina linux connectada a internet les 24h i amb el correu configurat
- Un dispositiu que pugui rebre correu electrònic per rebre l'alerta.
Primer crees una carpeta per al projecte:
mkdir /directori_de/disponibiliatatNexus
Després et baixes la pàgina de Google on encara no apareix el Nexus 5:
/usr/bin/wget -o /dev/null -O - https://play.google.com/store/devices \
| grep -v page-load-indicator > no.html
I ara escrius aquest script, li direm comprova.sh:
#!/bin/bash
cd /directori_de/disponibiliatatNexus
/usr/bin/wget -o /dev/null -O - https://play.google.com/store/devices \
| grep -v page-load-indicator > potser.html
diff no.html potser.html > /dev/null
if [ -a nomore ]
then
exit
fi
if [ $? -eq 1 ]
then
touch nomore
echo "Subject:Comprova diponibilitat nexus" | /usr/bin/sendmail el_teu@correu.cat
fi
Poses l'script al cron:
3,altres minuts,57 * * * * \
/directori_de/disponibiliatatNexus/comprova.sh 2>> \
/directori_de/disponibiliatatNexus/errors.log
I t'esperes a rebre l'avís.
That's all!
Necessitarem:
- Una màquina linux connectada a internet les 24h i amb el correu configurat
- Un dispositiu que pugui rebre correu electrònic per rebre l'alerta.
Primer crees una carpeta per al projecte:
mkdir /directori_de/disponibiliatatNexus
Després et baixes la pàgina de Google on encara no apareix el Nexus 5:
/usr/bin/wget -o /dev/null -O - https://play.google.com/store/devices \
| grep -v page-load-indicator > no.html
I ara escrius aquest script, li direm comprova.sh:
#!/bin/bash
cd /directori_de/disponibiliatatNexus
/usr/bin/wget -o /dev/null -O - https://play.google.com/store/devices \
| grep -v page-load-indicator > potser.html
diff no.html potser.html > /dev/null
if [ -a nomore ]
then
exit
fi
if [ $? -eq 1 ]
then
touch nomore
echo "Subject:Comprova diponibilitat nexus" | /usr/bin/sendmail el_teu@correu.cat
fi
Poses l'script al cron:
3,altres minuts,57 * * * * \
/directori_de/disponibiliatatNexus/comprova.sh 2>> \
/directori_de/disponibiliatatNexus/errors.log
I t'esperes a rebre l'avís.
That's all!
dissabte, 26 d’octubre del 2013
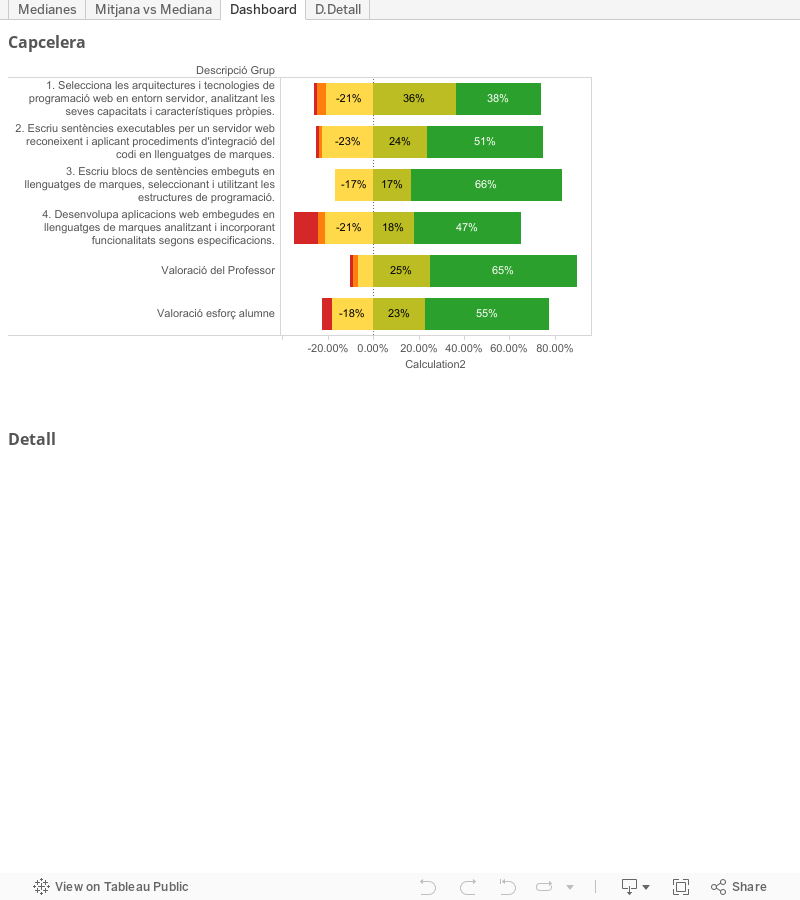
Autoavaluació MÒDUL 7: DESENVOLUPAMENT WEB EN ENTORN SERVIDOR
Autoavaluació
MÒDUL 7: DESENVOLUPAMENT WEB EN ENTORN SERVIDOR

Aquest és el resultat de l'autoavaluació anònima dels alumnes a la primera unitat formativa del mòdul professional DESENVOLUPAMENT WEB EN ENTORN SERVIDOR
La valoració de cada ítem és del 1 al 5, essent 5 perfecte i 1 molt malament. A la representació gràfica la puntuació 3 ( corresponent a la nota de 'un 5' ) és considerada negativa i li assigno el color groc. La puntuació 4 i 5, són possitives i els assigno el color verd. El taronja i el vermell representen les pitjors puntuacions, el 4 i el 5.
Les conclusions al llegir els resultats és que la UF ha anat prou bé. No haver modificat cap CMS ha fet baixar molt la valoració del resultat d'aprenentatge 4. Els alumnes estan contents de l'esforç que han realitzat durant aquesta unitat formatica i, al marge de l'autoavaluació, jo també estic satisfet de l'interés que han mostrat a classe i el treball que han realitzat.
Hi ha hagut un despistat que ha valorat molt possitivament el resultat d'aprenentatge 4.6. Ho podeu veure en detall punxant a la pestanya 'D.Detall'
Espero que aquesta UF hagi servit per assentar els conceptes bàsics de la programació web: session-less, cookies, POST, GET, etc.
dilluns, 12 d’agost del 2013
Retention Visualization
L'indicador 'Retention' ens explica la quantitat de persones que repeteixen un servei. Per calcular l'indicador 'retention' cal anar als logs d'accés i 'cuinar' les dades. En aquesta pregunta de l'stackoverflow precissament demanen com fer aquest càlcul amb una consulta de mySql:
El principal problema per a cuinar aquestes dades és que el MySQL té una sèrie de limitacions respecte els seus competidors:

Per a escriure la select he hagut de sacrificar qualsevol rastre d'elegancia en una consulta sql:


 |
MySQL user retention and day to day |
- No disposa de taules de pivotació ( per transposar les dates a columnes tal com es veu a la imatge)
- No disposa de funcions analítiques.
- No disposa de generadors de dates ( ni tans sols generadors d'enters )
- No disposa de CTE per poder trencar la consulta en consultes més fàcils.
Amb tot això aquesta és la solució proposada i les dades resultants:

- Subqueries de subqueries.
- Passar format datetime a date com string.
- Generador d'enters fet a mà
el cas és que la select funciona i obté els resultats desitjats.
Però la gràcia de l'indicador és que serveixi per ajudar a prendre millors decissions. Això no és senzill de fer sense una bona visualització dels resultats. Mitjançant un petit programet python he generat resultats aleatòris per disposar d'una mostra més àmplia que serveixi d'exemple de visualització, i aquí la tenim:

Assenyalat en vermell els diumenges. Cada dada deixa una estela que va decrementant-se. El punt més elevat representa el número de persónes que ha utlitzat el suposat servei i, l'estela, serien les persones que han repetit l'experiència el dia posterior, dos dies més tart i així fins a 7 dies, tal com demanava l'autor de la pregunta.
Una altre visualització de les mateixes dades, intercanviant fileres per columnes, seria aquesta:

Veiem per exemple que el dia 21 de juliol s'hi van connectar 486 persones, d'aquestes, el dia 22, es van tornar a connectar la majoria, no totes, i així seguiriem l'estela fins arribar a 7 dies més tart on veiem que van fer 'retention' unes 75.
Aquí el codi del programa pyton que genera les dades aleatòries:
from datetime import date, timedelta
import random
dia = date.today()
for n in range(50):
dia = dia - timedelta( days = 1 )
inicial = random.randint( 300, 500 )
print ( dia, dia, 0, inicial, sep=",")
for r in range( 1, 8 ):
resta = random.randint( 20, 100 )
inicial -= resta
if inicial > 0:
print ( dia, dia - timedelta( days = r ), r, inicial, sep="," )
dimecres, 7 d’agost del 2013
Google Trends: Recerques sobre estudis superiors.
Indicador:
Quantitat de recerques a Google ( territori 'spain' ) dels termes
'Grado Superior' v.s 'Universidad'
He assenyalat en taronja els mesos de maig i juny que són els mesos en que els alumnes busquen informació per a la matrícula. També el setembre en verd.

Interpretació:
La meva pregunta sobre el gràfic és per què al setembre hi ha més recerques que al juny (o maig) sent aquestes dates quan els alumnes decideixen els estudis que faran. D'altre banda, no sembla que el gràfic tingui relació amb l'interés o matriculacions dels alumnes a la Universitat (no he buscat dades comparatives) però seria interessant saber per què hi ha aquest descens de les cerques sobre el terme 'Universitat'. D'altre banda, queda clar que el pitjor moment per invertir en una campanya publicitària online seria el Nadal.
Gràfic al google trends:

Actualització de l'article
He descarregat de l'INE les dades de presentats i aprovats de les PAU. Sembla un bon indicador per a comparar-ho amb les recerques a google de la paraula 'Universitat'. Observem que no hi ha una correlació entre les recerques entre el mot 'Universitat' i la gent que es prepara per als estudis universitatis:

Nota: L'any 2013 no és comparable doncs hi ha dades només fins agost.
He descarregat de l'INE les dades de presentats i aprovats de les PAU. Sembla un bon indicador per a comparar-ho amb les recerques a google de la paraula 'Universitat'. Observem que no hi ha una correlació entre les recerques entre el mot 'Universitat' i la gent que es prepara per als estudis universitatis:

Nota: L'any 2013 no és comparable doncs hi ha dades només fins agost.
dimarts, 14 de maig del 2013
GHAP-BI: OLAP project with only open source tools
At this time, we are finishing the second course that GHAP is running. GHAP is an attendance control software and plus.
Previous GHAP feature was the ability to predict students attendance, a mix of Knime decision tree model and python lxml module to read resulting PMML.
 The new GHAP big feature is the Business Intelligence module. GHAP is for public schools, for this (and other) reason only free software tools should be included. I'm used to develop BI projects but this is my first one with open software tools. In this post I explain GHAP-BI software components and experience.
The new GHAP big feature is the Business Intelligence module. GHAP is for public schools, for this (and other) reason only free software tools should be included. I'm used to develop BI projects but this is my first one with open software tools. In this post I explain GHAP-BI software components and experience.
As any BI solution GHAP-BI incorporates ETL and Data Analysis and visualization software.
ETL is splitted as E+TL. The Extraction phase is made directly by GHAP application (django) and Transform and Load is made with pygrametl. This tool, pygrametl is praiseworthy: it is easy, fast and powerful and also clear documentation is available.
I prefer OLAP solutions over Reporting solutions, I appreciate metadata layer with measures and dimensions, for this reason I have included Saiku software as viz software. I found Saiku through a post in stackoverflow.

ETL development: GHAP generates each night a 91MB text file (>500K lines), it takes over 4 hours to complete export. This file contains 1 course attendance controls full detailed. Then, a little python code load this data into Warehouse database. In 2 minutes all data is imported over 5 tables in snow-flock design. pygrametl is the piece that makes this possible combining dimension cache with bulk facts import. Notice that pygrametl could reduce drastically also export time avoiding database lookups, but I prefer to generate first text file.
Viz: Saiku is the front end for the users. You can learn about Saiku Pros and Cons reading @twn08 post, but this is my experience: I send GHAP-BI url, user and passwd to manager, 20 minutes later I move to manager's office to know if connection was successful and my surprise was to see Saiku page with a combination on filters, dimensions and measures and also with some sorted data! When user see me the question was: "how can I export this viz?" I realized than Saiku is a very friendly tool. Install Saiku is easy, I have apt-get installed tomcat6 and copy Saiku "binary" files into tomcat webapps folder, then change connections and schema.
DataWarehouse backend: Saiku perform MDX queries to Mondrian and Mondrian translate it to Relational Database. I have test with both MySQL and Postgres, this one, Postgres, is definitely the option adopted. Postgres serves in seconds queries that run forever in MySQL.
Cubes: I have wrote cube schema initially with Pentaho Schema Workbench, but I have left it when I have transformed dimensions to shared dimensions.

Summarizing, In 20 hours my open software BI solution was successfully running, thanks to: python, django, Saiku, Postgres and pygrametl.
Previous GHAP feature was the ability to predict students attendance, a mix of Knime decision tree model and python lxml module to read resulting PMML.

As any BI solution GHAP-BI incorporates ETL and Data Analysis and visualization software.
ETL is splitted as E+TL. The Extraction phase is made directly by GHAP application (django) and Transform and Load is made with pygrametl. This tool, pygrametl is praiseworthy: it is easy, fast and powerful and also clear documentation is available.
I prefer OLAP solutions over Reporting solutions, I appreciate metadata layer with measures and dimensions, for this reason I have included Saiku software as viz software. I found Saiku through a post in stackoverflow.

ETL development: GHAP generates each night a 91MB text file (>500K lines), it takes over 4 hours to complete export. This file contains 1 course attendance controls full detailed. Then, a little python code load this data into Warehouse database. In 2 minutes all data is imported over 5 tables in snow-flock design. pygrametl is the piece that makes this possible combining dimension cache with bulk facts import. Notice that pygrametl could reduce drastically also export time avoiding database lookups, but I prefer to generate first text file.
Viz: Saiku is the front end for the users. You can learn about Saiku Pros and Cons reading @twn08 post, but this is my experience: I send GHAP-BI url, user and passwd to manager, 20 minutes later I move to manager's office to know if connection was successful and my surprise was to see Saiku page with a combination on filters, dimensions and measures and also with some sorted data! When user see me the question was: "how can I export this viz?" I realized than Saiku is a very friendly tool. Install Saiku is easy, I have apt-get installed tomcat6 and copy Saiku "binary" files into tomcat webapps folder, then change connections and schema.
DataWarehouse backend: Saiku perform MDX queries to Mondrian and Mondrian translate it to Relational Database. I have test with both MySQL and Postgres, this one, Postgres, is definitely the option adopted. Postgres serves in seconds queries that run forever in MySQL.
Cubes: I have wrote cube schema initially with Pentaho Schema Workbench, but I have left it when I have transformed dimensions to shared dimensions.

Summarizing, In 20 hours my open software BI solution was successfully running, thanks to: python, django, Saiku, Postgres and pygrametl.
Subscriure's a:
Missatges (Atom)